Yesterday I demonstrated that a poker statistic generated from a small amount of data is unreliable. More data = more reliable statistics.
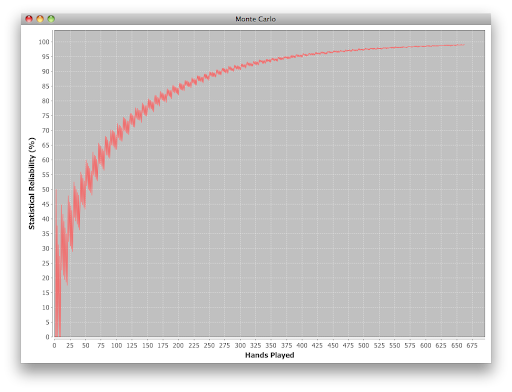
Just how much data do you need to use the statistics reliably? I found the answer through a Monte Carlo simulation showing how likely it is that a statistic is within +/- 5% of the opponent’s real playing style:
After 275 hands, 90% of stats based upon # of times seen are within +/- 5%. After 400 hands, 95% of the stats are pretty accurate.
[Note: Take this as a guide only. I made some simplifying assumptions]
Be really, really wary
95% chance of pretty good accuracy sounds good right? Does that mean that if you have played all your current opponents 400 times, then you can trust the statistics? No, for two reasons:
1) This only includes statistics based on “# of times seen”. Many statistics are based on much less frequency occurring situations.
2) Poker Copilot has 18 HUD statistics. If you have 8 opponents, that’s 18 times 8 = 144 statistics available. If each of these have a 95% chance of being accurate, then it is very likely at any given time that several of these stats do not realistically represent some aspect of an opponent’s playing style.
To conclude, as I wrote in the part 1: Statistics are only reliable if they are based on a large enough sample space. The larger the sample space, the more reliable the stats.
Yesterday’s post generated some strong replies. I was taken aback by this. The post was supposed to be an introduction to the tricky topic of interpreting poker tracking statistics.
The best response was from loyal customer Matt, who wrote,
People who pay $60 [for poker statistics software] are a sophisticated crowd.
He’s right. When people ask to export data from Poker Copilot for use with R I know I’ve got some mathematically sophisticated users.
What Matt and others don’t see are the support e-mails I get from some users without a strong background in statistics. They get lost amongst the statistics, unsure what to make of them. These users were the target for the post.
These are the users who might see that an opponent has a 0% “blind steal attempt”, and therefore fold their premium hand when that opponent does finally attempt to steal the blinds. But that 0% may be 0 from 4. In my opinion, folding here is a dangerous conclusion.
I say other users. But now a confession. I find myself instinctively playing by small-sample-space statistics sometimes. And I should know better!
I get requests to split the Poker Copilot HUD statistics into streets and positions. People want to know how often their opponent Bob folds to 3-bet on the river when on the button.
There’s no technical challenge to offering this. But I’d be doing you a disservice by giving you this information. Because it would be of no use. Unless you spent too much time reading statistical textbooks, you might try to use the info. Making decisions with bad info is not good.
Here’s the basic principle: Statistics are only reliable if they are based on a large enough sample space. The larger the sample space, the more reliable the stats.
Let me try to explain. Consider the “folds to three bet” statistic. Imagine Bob, in the long run, all else being equal, folds to a three bet 50% of the time.
If we have data for Bob being in this situation only once, he either folded or he didn’t fold. So the statistics would show that he “folds to three bet” either 0% or 100% of the time. Both of these stats are as wrong as it is possible to be. Whatever conclusion you draw from this data is baseless.
So we keep playing against Bob and collect more data. Now he’s faced a 3-bet four times. He folded either once, twice, three times, or four times. So his stat will be 0%, 33%, 67%, or 100%. These numbers are still unhelpful. Remember Bob’s true tendency in the long run is to fold to 3-bet 50% of the time, but the closest we get with these stats is still way off. A casual look at, say 67% will give the impression that Bob is scared of 3-bets. If the stat shows 33%, you’ll think he is quite brave. Any decision you make based on this data is working from false assumptions.
How many times would you need to play against Bob to get a reliable stat? Lots. If you want the stat to be accurate within 5% at least 50% of the time, you’d need to see Bob face a 3-bet 21 times. Based on my Poker Copilot database of 9-player ring game no-limit hold’em, people face a three-bet preflop once every 23 games on average. To gather enough data on a player to have a “within 5%” accuracy for half the time, you’d need to play against that player almost 500 times.
Play against Bob 500 times and you’ll have a sort-of, but not-quite reliable “folds to 3-bet” stat.
Is there any possibility of me accessing the Poker Copilot database?
Here’s my answer:
I intend to open the database soon. There’s not much to be gained by secrecy because a knowledgeable and enthusiastic Java programmer with JDBC experience could work it how to reverse engineer the database pretty easily anyway.
Also, I like the idea of an ecosystem of third-party extensions for Poker Copilot.
I think it’s awesome that you personally answer emails. I imagine you would have your minions do it however.
If only I had minions…I tried ordering some on the Internet, but they were sold out.
I have considered employing some part-time help for support issues, but I decided against it. That’s a level of commitment to another human being that I’m not ready for. Part of the joy of having a one-person software company is that there is, well, only one person. It makes me highly independent.
If things do grow beyond what I can handle by myself, I tentatively plan to look for more things to out-source. Beyond that, I’ll look for assistance on a part-time contract basis.
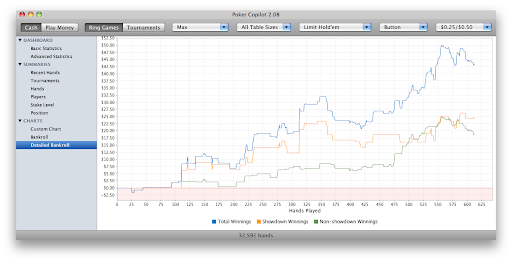
Here’s a screenshot showing what’s coming in the next Poker Copilot update: filtering by position and stake level.
I’ve changed the database structure for these new filters, so I need to create a “it-just-works” database update procedure. It’s a challenge, but I like challenges. It keeps the work interesting.